Introduction to RAG: 101
Let's travel to the world of RAG together.
A common scenario:
You published a book on Generative AI on March 27th of this year. However, the Large Language Model (LLM) you’re using was last trained on March 26th. As we know, LLMs don’t have access to information beyond their last training cutoff.
So, from the model’s perspective, your book doesn’t exist—it’s invisible. You can't ask it questions about the book or expect it to summarize or reference its contents. This brings us to the key question:
“How can I teach the LLM about my book?”
There are several approaches to solve this problem:
Using Agents
One way is to use agents that retrieve information from your book and present it to the user in response to queries. This can be effective in many cases.
But is it feasible in all situations?
Not always. Here’s why:
If your book is extensive, the agent must search through the entire content, or at least across targeted indices, to find relevant information. This process can be resource-intensive and may not scale efficiently.
Using Fine-Tuning
Another approach is fine-tuning—training the LLM with your book's content so that it becomes familiar with the material and can respond to queries naturally.
Sounds ideal, right?
But what if your book is updated frequently?
Then this method becomes less efficient. Here’s why:
Fine-tuning is both time-consuming and costly. Every time you update the book, you’d need to retrain the model with the new content, which is not practical if updates are frequent. In such cases, fine-tuning becomes a resource-draining solution.
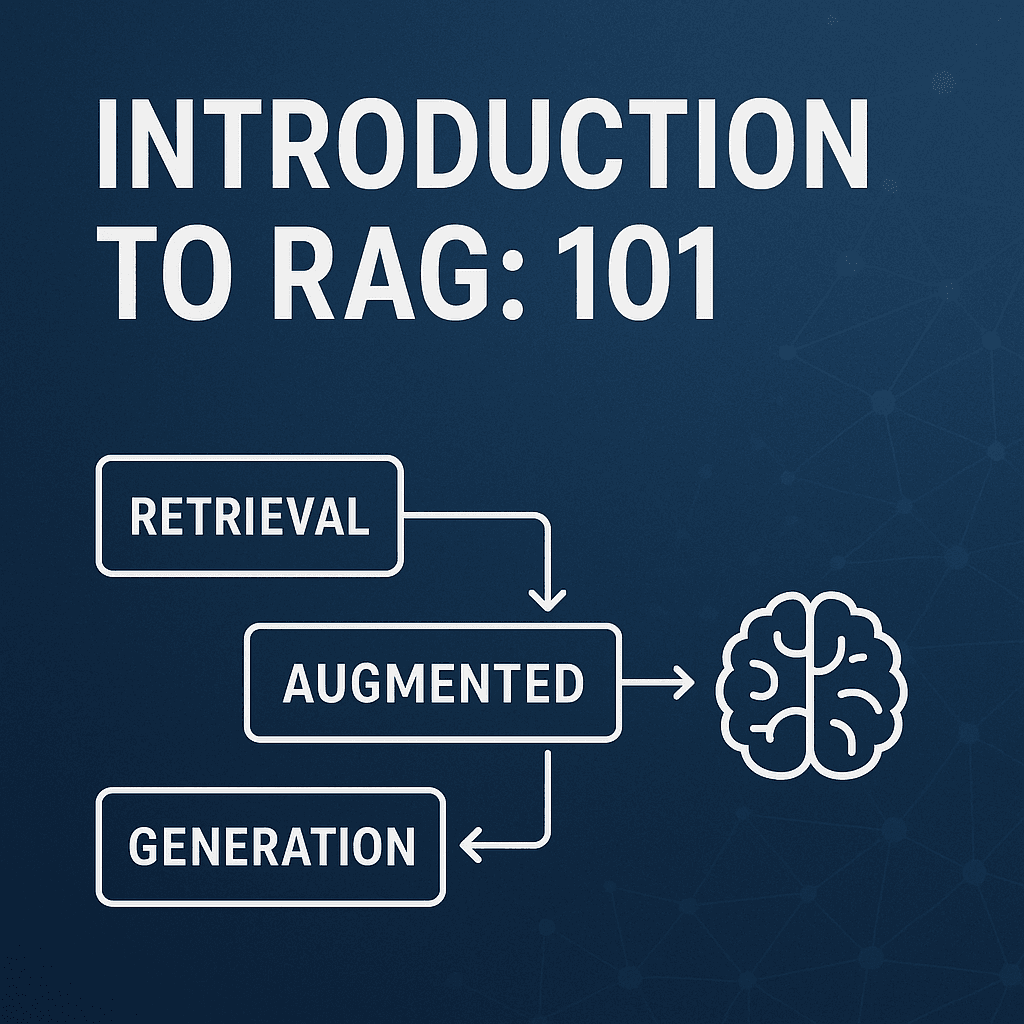
What is RAG?
Retrieval-Augmented Generation is a hybrid framework that combines two key features of modern AI systems:
Information retrieval and
Text generation
It was first introduced by Facebook AI in 2020 to overcome the knowledge gaps of the LLMs. Let’s dissect the terms to understand better:

1. Retrieval:
At its core, it means fetching relevant information from an external knowledge source (e.g., databases, vector stores, documents, websites, etc) at the time of the query. Process:
Instead of relying on what the model “knows”, it performs a search on the given sources.
The sources can be a vector store, a database, or anything that has the relevant information.
It is like asking the model to “look something up” before answering.
2. Augmentation:
“Augmented” means “enhanced with extra capabilities.” In this context:
The retrieved documents are injected into the model’s context (as prompts) before generating the answer.
Some extra operation is done on the retrieved data to help the model understand the context better.
This helps the model to augment/enhance its “knowledge base“ in real time
3. Generation:
This step is easy. Process:
Now, the model has the “context” it needed. Based on the context, it generates meaningful answers.
This is the actual question and answer phase, based on both the input query and the fetched context.
Yeah, this is the core process that happens in RAGs.
A simple application:
1. Retrieval:
I will follow these procedures:
Fix the Data Source: Here, the data source is your book.
Fragmentation/Chunking: Divide the data into smaller fragments/chunks so that I can do operations on the data efficiently. (Chunking itself is an art. Will get back to it in some other article, stay tuned 🥰)
Embedding: Embed the books’ data into the vector store (qdrant, Pinecone DB, etc.) so that I can easily search for similarity.
Store: Store the embeddings in the vector store.
User query embed: Get the user query and embed that also. (Need similar things to search, right?)
Search: Finally, search the similarity according to the embeddings of the user query.

2. Augmentation:
I would like to follow this procedure:
Prompt the AI: Will feed the context to the API. Here, will feed similar data to the AI.
Generate similar queries: You can skip this part. But it is good to give the AI more context. What if the user gives very dull queries🤔?
Now, the LLM model knows the context of the query that the user has asked. 🙂

3. Generation:
Feed all the queries.
Get the result.

Yeah, this will happen in the RAG for your book’s chatbot. Here’s the whole picture:

Why RAG matters:
In this whole process, did I use any agents?
-Yes, retrieval part, right?
And how much agents did I use? Just on some smaller parts (chunks), right? Is it more efficient than traversing through the whole dataset?
-Of course.
And Fine-Tuning? Did I hardcore Fine-tune the model? No, right?
So, in short, RAG meets most of the “Real-World” applications and can interact with live knowledge. This fits almost in all situations nicely. 🙂
Conclusion:
RAG itself is very complex. I have only shown a very basic use case. In future articles, I will discuss on more complex systems. Stay tuned. 🥰🥰🥰