Fine Tuning and more...
Let's find out what is fine-tuning and why is it needed
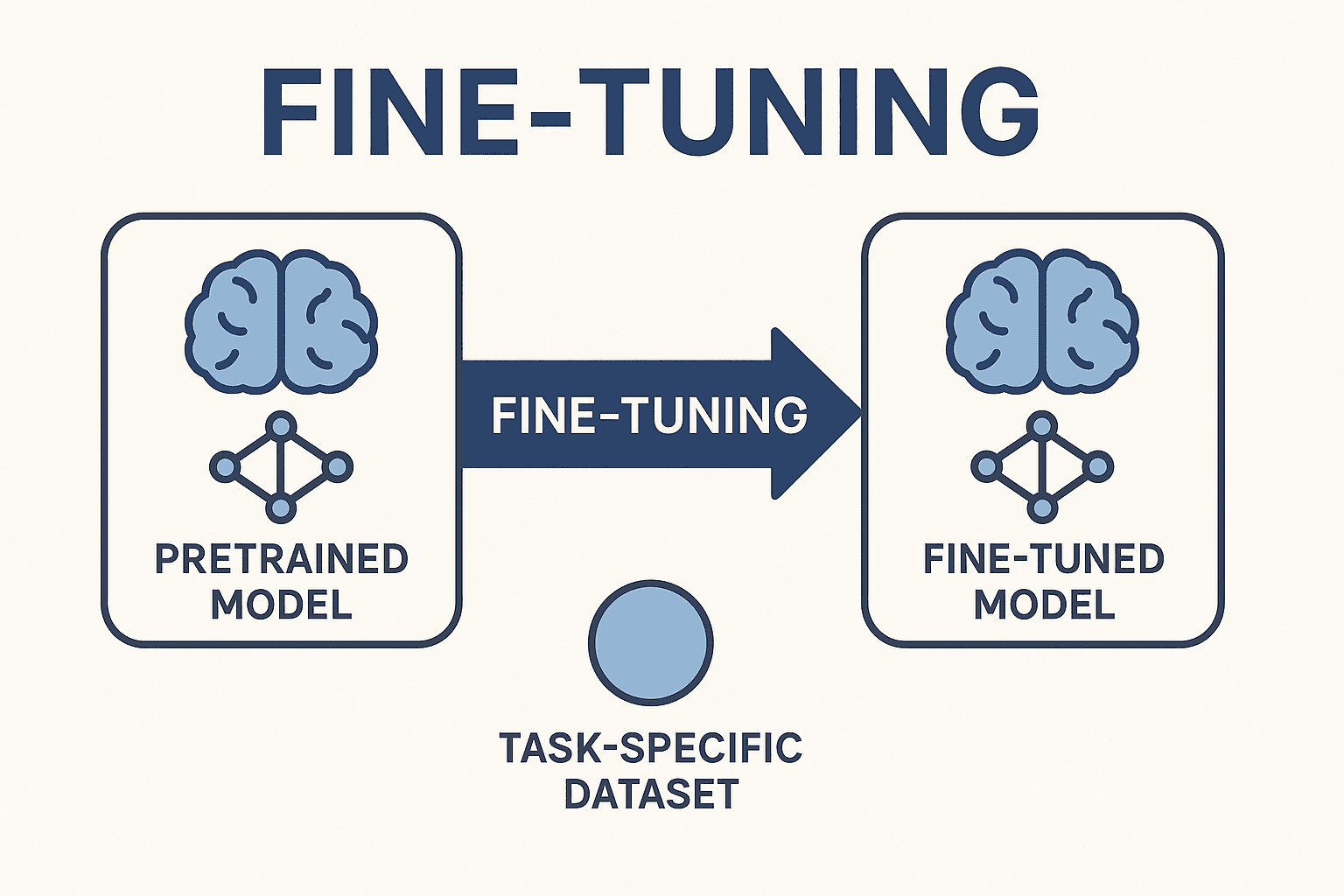
What is Fine-Tuning?
First, let me create a scenario:
Suppose an LLM model trained its dataset on 25th March and you have started a business from 27th March of the same year. We all know that every model available now has a cut-off time, right? That means each pre-trained model can have all the data available on the dataset until a fixed date and after that, it does not know anything. So, as you started late, the LLM model itself does not know anything about your business. Now, you have a problem.
“How can the users get the latest/important data of your business???“
You can solve this problem by several methods:
Use AI Agents: You can use agents to scrape data from the internet. But this works on a very shallow level and cannot answer any query that is not on the internet.
Train the AI model: There is another approach. Train the LLM model on your business data and open the data for the users to query on that so that it can answer thoroughly on the business. This thing is better than just using some agents.
Here, you trained your model on your data and made a transformed model to meet your needs, “THIS IS CALLED FINE-TUNING”. Let’s see the formal definition…
Definition:
*“*Fine-tuning is the process of taking a pre-trained model (typically on a large, general dataset) and further training it on a smaller, task-specific dataset to adapt it to a particular problem.“
Why is this needed?
Easily speaking, to fit the LLM model according to some specific needs. This thing also helps in these cases:
It can reduce computing costs and training time
Can work on smaller datasets
Can give better performance
Process of Fine-Tuning:
To Fine-Tune a model these steps are followed:

Methods of Fine-Tuning:
There are several methods of fine-tuning:
Full Fine-Tuning (also known as Full Parameter Fine-Tuning)
Partial/Layer-wise Fine-Tuning
LoRA Fine-Tuning
PEFT (Parameter-Efficient Fine-Tuning)
Now, let’s elaborate on some of these.
Full Fine-Tuning:
In full Fine-Tuning, you adjust the actual weights of the pre-trained LLM model through Forward Propagation, Loss Calculation, Back Propagation, and then Weight Update.
This method provides the most accurate solution, with a low risk of incorrect information. It works well for smaller models, but it's not as efficient for larger ones. Why?
Because you need to update the entire LLM, and training a whole model is very costly in terms of hardware and time. If you want to train a model often, it will use a lot of resources, which isn't practical.
LoRA (Low-Rank Adaptation) :
Earlier, we saw that training the entire model (actual LLM) is very expensive. So, what if instead of training the whole model, we create a separate memory space to store the differences in responses based on queries from the actual model? Then, when we ask the model something next time, we add these differences to the response to get the desired answer. This is the process of the “Low-Rank Adaptation” method.
A little bit of confusing, right?
Let’s answer this, “How do the LLM models generate responses???”
-Doesn’t it find the nearest values from its vector embeddings? Isn’t it just the next token prediction?
-Yes.
So, in the end, everything operates on some numbers, right? So, if we calculate how much a response token is deviated from our desired token and then on our next query add the deviation with the response token, won’t we get our desired response? Yeah, sure we are. This is the main idea behind this process. Let’s see diagrams:


The first diagram runs for the first time and trains the new LLM model with fine-tuned data. For each query, the second diagram then runs.
This process is very time-efficient. I mean you do not need to change the original LLM, but make a new temporary model and use its deviation, simple!!!
But it consumes a lot of memory (trade-offs between memory and time). And as it runs on deviation, it does not work very well where precision matters.
I will not discuss the other two, will leave them to you!!!
Some insight on LoRA:
Let’s say we have a weight matrix in an LLM with dimensions m × n. Fine-tuning such large matrices directly can be computationally expensive and memory-intensive.
This is where LoRA (Low-Rank Adaptation) shines.
Instead of updating the full m × n matrix during fine-tuning, LoRA introduces a “delta” matrix — a learned adjustment to the original weights. Due to the nature of most tasks, this delta matrix tends to be sparse (mostly zeros) and low-rank, meaning that only a small subset of changes actually matter.
Here’s the clever part:
Rather than modifying the full matrix, LoRA decomposes it into two smaller matrices of shapes m × r and r × n, where r « m, n. Fine-tuning is applied to these smaller matrices. During inference, they are multiplied and added back to the original weights, reconstructing the adapted transformation.
This approach:
Preserves performance
Minimizes memory and compute overhead
Allows parameter-efficient fine-tuning even for very large models
That’s the core idea: train small, plug back smartly. LoRA makes large-scale model adaptation practical and scalable.
Use cases of Fine-Tuning:
Heavily used in chatbot training
Code completion for specific languages
Image classification system (eg, Medical Sectors)
etc.
Conclusion:
Fine-tuning is a way to get data specific to a system. There are many other methods (like Agents, RAG, etc.), but for certain needs, where adding an extra layer for a specific use case on an LLM is needed for a while, Fine-Tuning works well.