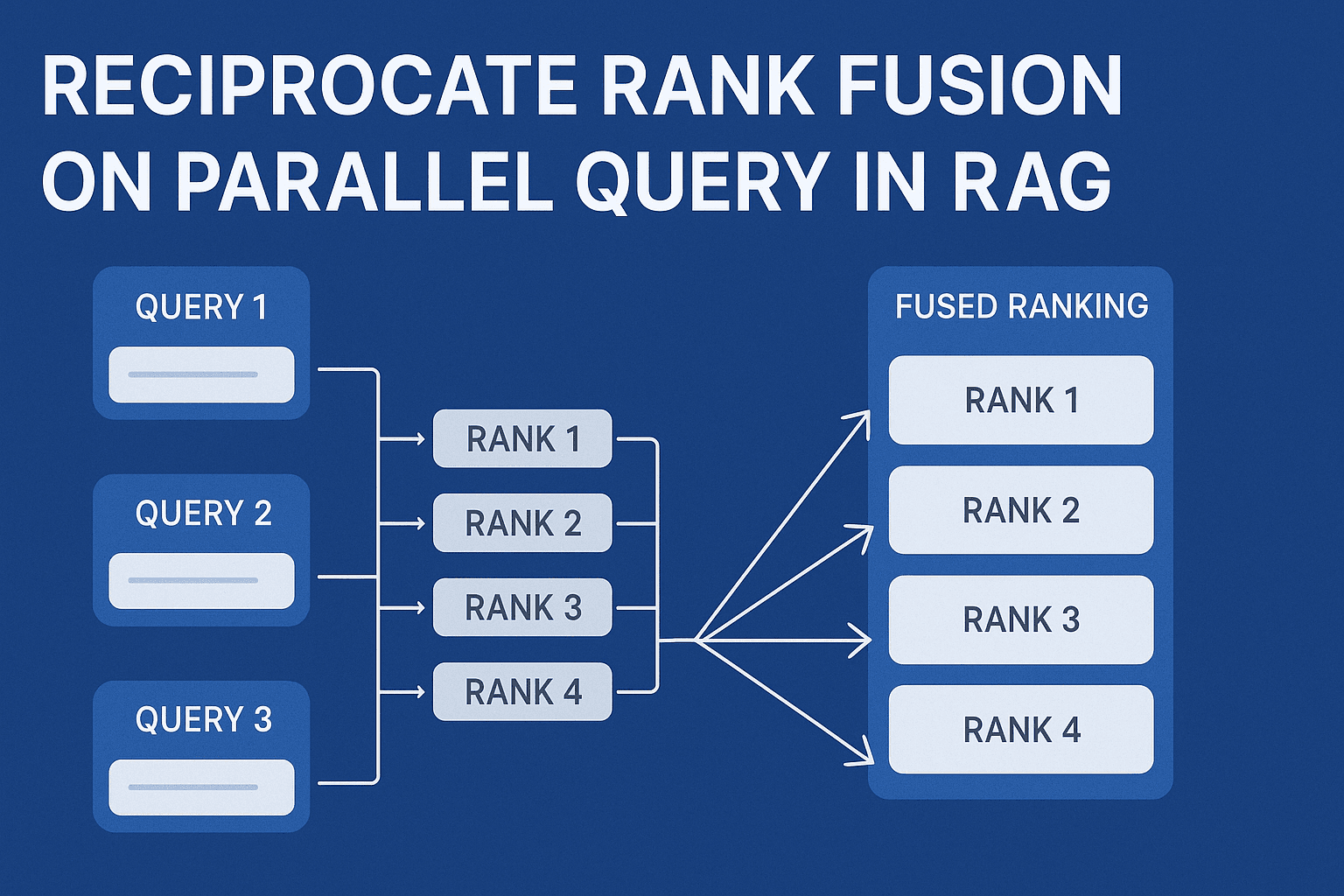
Reciprocate Rank Fusion (RRF)
Another optimization technique - Ranking
Remember:
Previously, we made a RAG model with Parallel Query Retrieval (Fan Out system). If you did not read it, just click on the name “Parallel Query Retrieval.” I will take some context from there.
Context:
You did give a documentation of Node.js to the RAG model and asked, “What is fs?” But the documentation did not have the word “fs” in it. To solve this,
The LLM generated some similar questions (parallel query generation):
What is the file system?
What is a file in Node.js?
How to create a file in Node.js?
Then you searched these terms in the “Vector Store” and found this:
You could not find anything for the question “What is fs?”
You found 2 similarities for the question “What is the file system?” (just denoting: one yellow, one blue)
You found one similarity for the question “What is a file in Node.js?” (one blue)
You found three similarities for the question “How to create a file in Node.js?” (one blue, one yellow, one red)
The diagram was like this:

Yeah, this response is somewhat optimized, but in a large context, it will lose its relevance and credibility, right? This problem gives birth to a new term, “Reciprocate Rank Fusion”.
What is Reciprocate Rank Fusion (RRF)?
Some insights:
Some hefty words, huh? Well, “Reciprocate Rank Fusion” just means “Rank Them”, simple!!!
Now, the million-dollar question: “How will you rank them?” There should be two criteria, right?
Sort the results on the total appearance in descending order.
If the total appearances for two results are the same, sort them in the order of appearance (1st, 2nd, 3rd).
This is the main idea. It‘s time to do a dry run. Look at the diagram below:

Now, notice the observations:
We found 2 similarities for the question “What is the file system?” (just denoting: one yellow, one blue). Yellow was 1st, Blue was 2nd.
We found two similarities for the question “What is a file in Node.js?” (one blue, one red). Blue 1st, and Red 2nd.
We find three similarities for the question “How to create a file in Node.js?” (one blue, one yellow, one red). Blue is 1st, Yellow is 2nd, and Red is 3rd.
So, the final observation:
Blue has 3 appearances. So, it will be placed in the first position.
Yellow and Red both have appeared twice. But, Yellow appeared before the Red more frequently. So, Yellow will be 2nd.
Red will be 3rd.
Wow, ranking done!!! Now, your result has more relevance than just retrieving data in parallel.
Intuition:
If a document ranks higher in multiple lists (even if it doesn't appear in all), it’s probably important and gets a better final score.
Definition:
Reciprocal Rank Fusion (RRF) is a simple yet powerful method used to combine multiple ranked lists of documents (or responses, answers, items, etc.) into a single fused ranking.
Formula:
$$\text{RRF_score}(\text{document}) = \sum_{i=1}^{n} \frac{1}{k + \text{rank}_i}$$
This generally means to add the reciprocal of the ranks added with a constant k (generally 60) throughout all the results. Let’s take a few more examples to understand this:
## User query:
"What is polymorhism?"
## LLM Generated queries
queries = [
"What is polymorphism?",
"Types of polymorphism in OOP",
"How does polymorphism work?",
"Polymorphism examples"
]
## Example results:
Query 1 results: [Page15, Page16, Page18, Page20]
Query 2 results: [Page16, Page15, Page17, Page19]
Query 3 results: [Page15, Page18, Page16, Page21]
Query 4 results: [Page17, Page15, Page20, Page16]
**Here 3 pages appeared: Page15, Page16 and Page17**
# RRF Calculations:
Page15_RRF = 1/(60+1) + 1/(60+2) + 1/(60+1) + 1/(60+2) = 0.0164 + 0.0161 + 0.0164 + 0.0161 = 0.0650
Page16_RRF = 1/(60+2) + 1/(60+1) + 1/(60+3) + 1/(60+4) = 0.0161 + 0.0164 + 0.0159 + 0.0156 = 0.0640
Page18_RRF = 1/(60+3) + 0 + 1/(60+2) + 0 = 0.0159 + 0 + 0.0161 + 0 = 0.0320
## Final ranking: Page15 (0.0650) > Page16 (0.0640) > Page18 (0.0320)
Why k=60?
Look at the examples below:
# Without k constant:
Rank 1: 1/1 = 1.0
Rank 2: 1/2 = 0.5 ← 50% drop! Too harsh!
Rank 3: 1/3 = 0.33 ← 67% drop from rank 1
# With k=60:
Rank 1: 1/(60+1) = 1/61 = 0.0164
Rank 2: 1/(60+2) = 1/62 = 0.0161 ← Only 2% drop
Rank 3: 1/(60+3) = 1/63 = 0.0159 ← Only 3% drop from rank 1
So, we need a constant value for stopping the value from dropping suddenly, and “60” is an experimental value that works well in almost every situation.
🧠What does the word “Reciprocal” mean?
Great question!
When we were analyzing and combining query results, we needed a way to fairly rank documents that appeared across different queries. Instead of simply assigning points based on ranks and summing them up, we used the reciprocal of the rank values.
Why? Because taking the inverse (or reciprocal) of a rank gives higher weight to top-ranked results while still allowing lower-ranked results to contribute. This method helps stabilize the scoring and makes the system more robust.
In the RRF formula, we take the rank of a document (like Page15), add a constant k (usually 60), and then invert the result. We repeat this for each query where the document appears and sum them up. This "reciprocation" is where the name Reciprocal Rank Fusion comes from.
In short:
Our general discussion is done. Let’s move to some code:
Some examples:
def perform_parallel_search_with_rrf(vector_store, queries, k_per_queries, rrf_k=60, min_similarity_threshold = 0.4):
"""Perform search with multiple queries and combine results"""
all_documents = {}
query_results = {}
# Running parallel search on it.
for index, query in enumerate(queries, 1):
print(f"Runnung search on query {index}: {query}")
query_results[query] = []
response = vector_store.search(query, k=k_per_queries)
# Checing relevance of the response. The lower, the better.
# Notice, this is the score generated by the search function or Qdrant DB and
# according to them the similarity score should be lower to be more relevant after search
# Check out this: https://qdrant.tech/documentation/concepts/search/
# This is not same as our RRF (this is extra)
relevant_results = []
for rank, (document, score) in enumerate(response, 1):
if score <= min_similarity_threshold:
relevant_results.append((rank, document, score))
else:
print(f"The response no. {index} is not relevant enough")
if not relevant_results:
print("No relevant results found, sorry")
continue
# Ranking begins
# We first calculate in which position the document appears for a query
for original_rank, document, score in relevant_results:
content_hash = hash(document.page_content[:100].strip())
page_number = document.metadata.get('page', 'unknown')
doc_id = f"page_{page_number}_{content_hash}"
if doc_id not in all_documents:
all_documents[doc_id] = {
'document': document,
'content': document.page_content,
'page': document.metadata.get('page', 'N/A'),
'source': document.metadata.get('source', 'N/A'),
'query_ranks': {},
'similarity_scores': {},
'rrf_contributions': {},
'queries_appeared': []
}
all_documents[doc_id]['query_ranks'][query] = original_rank
all_documents[doc_id]['similarity_scores'][query] = score # We save the Qdrant search score in here
all_documents[doc_id]['queries_appeared'].append(query)
rrf_contribution = 1/(original_rank+rrf_k) # We calculate the RRF contribution for each document for each query
all_documents[doc_id]['rrf_contributions'][query] = rrf_contribution
query_results[query].append({
'doc_id': doc_id,
'rank': original_rank,
'similarity_score': score,
'rrf_contribution': rrf_contribution
})
rrf_results = []
# We then arrange the RRF contribution wise results in here.
# We then sort the results
for doc_id, doc_data in all_documents.items():
total_rrf_score = sum(doc_data['rrf_contributions'].values())
num_of_queries_appeared = len(doc_data['queries_appeared'])
avg_rank = sum(doc_data['query_ranks'].values())/num_of_queries_appeared
avg_similarity = sum(doc_data['similarity_scores'].values())/num_of_queries_appeared
best_rank = min(doc_data['query_ranks'].values())
best_similarity = min(doc_data['similarity_scores'].values())
consensus_score = num_of_queries_appeared/len(queries)
rrf_results.append({
'document': doc_data['document'],
'content': doc_data['content'],
'page': doc_data['page'],
'source': doc_data['source'],
'rrf_score': total_rrf_score,
'consensus_score': consensus_score,
'num_queries_appeared': num_of_queries_appeared,
'avg_rank': avg_rank,
'best_rank': best_rank,
'avg_similarity': avg_similarity,
'best_similarity': best_similarity,
'query_ranks': doc_data['query_ranks'],
'similarity_scores': doc_data['similarity_scores'],
'rrf_contributions': doc_data['rrf_contributions'],
'queries_appeared': doc_data['queries_appeared']
})
rrf_results.sort(key=lambda x:x['rrf_score'], reverse=True) # We are sorting here.
return rrf_results
Full Code:
Some observations:
Did you notice that I applied the “RRF” technique on “Parallel Query Retrieval”? Is it necessary?
Is there any problem with this technique? Will it generate expected results every time? When will this technique “hallucinate”/”fail”?
Can you check this implementation by giving different inputs?
Conclusion:
“Reciprocate Rank Fusion” is just a fancy word. Under the hood, it just ranks the queries. Is it enough? I cannot say. There are a bunch of techniques that are better than the previous one. In the later articles, I will try to cover them. Stay Tuned!